在今天的內容中,我們不會像在Seq2Seq模型中那樣,所有元件都需要自己手寫。因為在Pytorch中,其實已經有幫我們定義好Transformer的框架。但由於Transformer中的運算是平行進行的,這個模型最麻煩的部分在於遮罩矩陣的設定,因此今天我們將使用NEWS SUMMARY數據集,來介紹這些矩陣的創建方式與實際用途。
而在本次內容中,由於我們的資料都是英文,因此在Tokenizer的部分只需要導入bert-base-uncased這一個英文的Tokenizer就好。而且這次我們除了使用該Tokenizer的input_ids之外,還會使用attention_mask來幫助我們產生對應的遮蔽矩陣。現在讓我們來看看完成的模型訓練過程吧!
在這一步中,由於資料本身就是 CSV 文件,因此我們不需要進行轉換,直接使用 os.listdir() 讀取資料即可。在這個資料欄中,text 為完整的新聞資料,summary 則為對應的摘要文字。我們需要將其讀取出來,將 text 給予 Encoder 運算,而將 summary 給予 Decoder 運算。
from transformers import AutoTokenizer
import pandas as pd
import os
def read_csv_data(data_path):
source, target = [], []
for file_name in os.listdir(data_path):
df = pd.read_csv(f'{data_path}/{file_name}')
src, tgt = df['text'].values, df['summary'].values
source.extend(src)
target.extend(tgt)
return source, target
x_train_data, y_train_data = read_csv_data('news/train')
x_test, y_test = read_csv_data('news/test')
tokenizer = AutoTokenizer.from_pretrained('bert-base-uncased')
接下來我們在建立 Pytorch DataLoader 時,需要從 Tokenizer 中取出 input_ids 與 attention_mask 這兩個參數。不過由於這些參數是分別提供給 Encoder 和 Decoder 的,因此我們需要在 collate_fn 中修改這些參數的鍵名稱,以便在後續撰寫模型的前向傳播時,更能清晰地了解這些參數的實際用途。
from torch.utils.data import Dataset, DataLoader
from sklearn.model_selection import train_test_split
class SummaryeDataset(Dataset):
def __init__(self, x, y, tokenizer):
self.x = x
self.y = y
self.tokenizer = tokenizer
def __getitem__(self, index):
return self.x[index], self.y[index]
def __len__(self):
return len(self.x)
def collate_fn(self, batch):
batch_x, batch_y = zip(*batch)
src = self.tokenizer(batch_x, max_length=256, truncation=True, padding="longest", return_tensors='pt')
tgt = self.tokenizer(batch_y, max_length=256, truncation=True, padding="longest", return_tensors='pt')
src = {f'src_{k}':v for k, v in src.items()}
tgt = {f'tgt_{k}':v for k, v in tgt.items()}
return {**src, **tgt}
x_train, x_valid, y_train, y_valid = train_test_split(x_train_data, y_train_data, train_size=0.8, random_state=46, shuffle=True)
trainset = SummaryeDataset(x_train, y_train, tokenizer)
validset = SummaryeDataset(x_valid, y_valid, tokenizer)
train_loader = DataLoader(trainset, batch_size = 32, shuffle = True, num_workers = 0, pin_memory = True, collate_fn=trainset.collate_fn)
valid_loader = DataLoader(validset, batch_size = 32, shuffle = True, num_workers = 0, pin_memory = True, collate_fn=validset.collate_fn)
在這一步開始,我們要建立Transformer的模型架構了。不過在Pytorch中並沒有為我們預設Positional Encoding,這是因為其實現方法多種多樣,且很多後續的改動也會針對Positional Encoding進行調整。因此Pytorch將這一部分的功能交給使用者自行定義。
在這裡我們的實際做法將遵照原始的方式進行,通過sin()與cos()的位置信息分別嵌入到傳給Positional Encoding的對應Embedding層中,而以下的程式碼都只是對應我們昨日所說明到的公式實現方式。
import torch
import torch.nn as nn
class PositionalEncoding(nn.Module):
def __init__(self, emb_size, dropout, maxlen=5000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
pe = torch.zeros(maxlen, emb_size)
position = torch.arange(0, maxlen, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, emb_size, 2).float() * (-torch.log(torch.tensor(10000.0)) / emb_size))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0).transpose(0, 1)
self.register_buffer('pe', pe)
def forward(self, x):
x = x + self.pe[:x.size(0), :]
return self.dropout(x)
不過我們需要注意一點,在 PyTorch 中self.register_buffer 是一個比較特殊的技巧,特別是當我們想要定義一些不需要參與模型訓練(不需要追蹤梯度)的變量時我們必須調用它。像是Positional Encoding是一個不會被模型訓練而改變的絕對位子,而這時使用常規的變量宣告方法,PyTorch 會默認追蹤梯度導致其位子有所變化,因此我們通過 register_buffer 的方式來避免這個問題。
在這裡我們同樣將模型拆成多個區段進行簡要講解,而在Transformer中其實非常簡單,我們只需要宣告兩者的Embedding與剛剛建立的PositionalEncoding組件,接著直接呼叫nn.Transformer與Decoder輸出時的nn.Linear。這些就是我們昨天繪製的Transformer中所包含的全部物件。我會把相關參數的函數寫在註解中,如果你看不懂註解,建議先回去看看昨日的模型架構圖,這樣你會更理解該模型的實際函數。
class Seq2SeqTransformer(nn.Module):
def __init__(self, vocab_size, emb_size, d_model, nhead, num_encoder_layers, num_decoder_layers, dim_feedforward):
super(Seq2SeqTransformer, self).__init__()
self.src_embedding = nn.Embedding(vocab_size, emb_size)
self.tgt_embedding = nn.Embedding(vocab_size, emb_size)
self.positional_encoding = PositionalEncoding(emb_size, dropout=0.1)
self.transformer = nn.Transformer(
d_model=d_model, # 對應的嵌入層維度跟emb_size相同大小
nhead=nhead, # Muti-head Attention head數量
num_encoder_layers=num_encoder_layers, # 要幾個Encoder進行運算
num_decoder_layers=num_decoder_layers, # 要幾個Decoder進行運算
dim_feedforward=dim_feedforward, # Layer Norm輸出維度
batch_first=True
)
# 用於生成最終輸出的線性層
self.fc = nn.Linear(d_model, vocab_size)
self.criterion = torch.nn.CrossEntropyLoss(ignore_index=tokenizer.pad_token_id)
而在前向傳播時,我們需要注意到 src_input_ids 與 tgt_input_ids 是分別給予模型的資料,此外還需提供Positional Encoding以賦予位置信息。因此我特別設定了一個 embedding_step 方法,讓我們能夠快速賦予其位置信息。
而在這裡最重要的部分是其遮蔽矩陣。昨日我們提到的遮蔽矩陣是只有Decoder為了遮蔽未來訊息的矩陣,但是實際上我們在進行運算時會有Padding的動作。因此我們需要從attention_mask中取出Padding的索引,但是在Transformer中,與其相反需要被填充的位置是1,未被填充的則是0。因此,在src_key_padding_mask的部分,我們可以看到我們簡單的轉換。
為了生成遮蔽未來訊息的矩陣,我們只需使用torch.triu來生成一個大小為emb_dim * emb_dim的遮蔽矩陣。此外,我們需要注意正如昨天所提到的,我們需要將矩陣中的0轉換為-inf,1轉換為0,這樣在模型計算softmax時才不會考慮被遮蔽的數值。
def forward(self, **kwargs):
src_ids = kwargs['src_input_ids']
tgt_ids = kwargs['tgt_input_ids']
src_emb, tgt_emb = self.embedding_step(src_ids, tgt_ids)
src_key_padding_mask = (kwargs['src_attention_mask'] == 0)
tgt_key_padding_mask = (kwargs['tgt_attention_mask'] == 0)
src_mask = torch.zeros((src_emb.shape[1], src_emb.shape[1]),device=device).type(torch.bool)
tgt_mask = self.generate_square_subsequent_mask(tgt_emb.shape[1])
# 將嵌入通過transformer模型
outs = self.transformer(
src_emb, tgt_emb,
src_mask=src_mask,
tgt_mask=tgt_mask,
src_key_padding_mask=src_key_padding_mask,
tgt_key_padding_mask=tgt_key_padding_mask,
memory_key_padding_mask=src_key_padding_mask
)
logits = self.fc(outs)
tgt_ids_shifted = tgt_ids[:, 1:].reshape(-1)
logits = logits[:, :-1].reshape(-1, logits.shape[-1])
loss = self.criterion(logits, tgt_ids_shifted)
return loss, logits
def embedding_step(self, src, tgt):
src_emb = self.src_embedding(src)
tgt_emb = self.tgt_embedding(tgt)
return self.positional_encoding(src_emb), self.positional_encoding(tgt_emb)
def generate_square_subsequent_mask(self, sz):
mask = (torch.triu(torch.ones(sz, sz)) == 1).transpose(0, 1)
mask = mask.float().masked_fill(mask == 0, float('-inf')).masked_fill(mask == 1, float(0.0))
return mask.to(device)
這裡其實有兩點不同。由於Encoder會將部分資訊傳送給Decoder,因此我們需要在這個過程中再次對Encoder中被Padding的序列進行Padding,這一個遮蔽矩陣就是程式中的memory_key_padding_mask。另一個遮蔽矩陣是src_mask,其功能是讓Decoder遮蔽未來的訊息。在原始的Transformer中,我們不需要這樣處理,因此可以直接將其設定為0。
我們需要完成生成的方式,這個過程其實與Transformer的前向傳播方式相同,也與Seq2Seq類似。我們會用for迴圈將BOS Token給模型,然後讓它生成下一個新序列,直到遇到Eos Token為止。其實這就是利用Seq2Seq的生成方式與Transformer的方式進行結合。
def generate(self, max_length=50, cls_token_id=101, sep_token_id=102, **kwargs):
src_input_ids = kwargs['input_ids']
src_attention_mask = kwargs['attention_mask']
# 先嵌入源序列
src_emb = self.positional_encoding(self.src_embedding(src_input_ids))
src_key_padding_mask = (src_attention_mask == 0)
# 初始化目標序列,開始符號 (BOS)
tgt_input_ids = torch.full((src_input_ids.size(0), 1), cls_token_id, dtype=torch.long).to(src_input_ids.device)
for _ in range(max_length):
tgt_emb = self.tgt_embedding(tgt_input_ids)
tgt_emb = self.positional_encoding(tgt_emb)
# Transformer 前向傳播
outs = self.transformer(
src_emb, tgt_emb,
src_key_padding_mask=src_key_padding_mask,
memory_key_padding_mask=src_key_padding_mask
)
logits = self.fc(outs)
next_token_logits = logits[:, -1, :]
next_token = torch.argmax(next_token_logits, dim=-1).unsqueeze(1)
tgt_input_ids = torch.cat([tgt_input_ids, next_token], dim=1)
# 停止條件: 如果生成的序列中包含了結束符號 (EOS)
if next_token.item() == sep_token_id:
break
return tgt_input_ids
最後,當我們設定好相關的參數後,就可以開始訓練模型的參數了。同樣地我們使用Trainer進行訓練。不過這次,我們會使用Warmup加餘弦退火法進行訓練。該算法在一開始使用Warmup,以確認學習的方向,然後通過Cos波型不斷調整模型的學習率,使其能夠達到最佳收斂。
# 設定模型
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = Seq2SeqTransformer(
vocab_size=len(tokenizer),
emb_size=512,
d_model=512,
nhead=8,
num_encoder_layers=6,
num_decoder_layers=6,
dim_feedforward=2048
).to(device)
import torch.optim as optim
from transformers import get_cosine_with_hard_restarts_schedule_with_warmup
from trainer import Trainer
# 優化器與排成器
optimizer = optim.AdamW(model.parameters(), lr=1e-4)
scheduler = get_cosine_with_hard_restarts_schedule_with_warmup(
optimizer,
num_warmup_steps=len(train_loader),
num_training_steps=len(train_loader) * 100,
num_cycles=1,
)
# 訓練模型
trainer = Trainer(
epochs=100,
train_loader=train_loader,
valid_loader=valid_loader,
model=model,
optimizer=[optimizer],
scheduler=[scheduler]
)
trainer.train(show_loss=True)
# ----- 輸出 -----
Train Epoch 29: 100%|██████████| 4643/4643 [06:25<00:00, 12.04it/s, loss=0.390]
Valid Epoch 29: 100%|██████████| 1161/1161 [00:33<00:00, 34.50it/s, loss=0.950]
Train Loss: 0.34809| Valid Loss: 2.26407| Best Loss: 2.18540
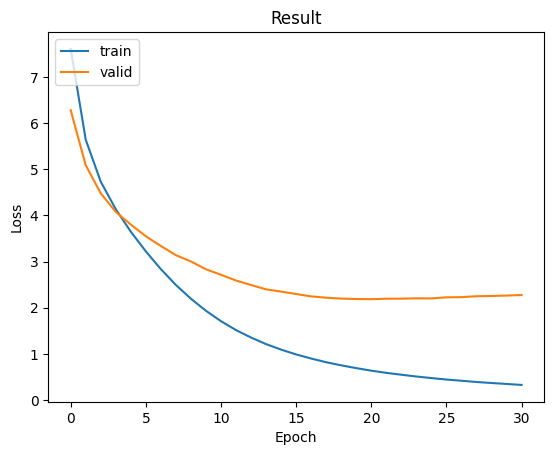
最終我們所看到的結果是目前訓練效果最好的曲線,這是由於Transformer強大的架構,再加上我們利用排程器進行優化,使其能夠呈現出極佳的曲線。
我們可以直接調用generate方法進行生成,從生成的結果中可以看出,其生成的文字與實際情況並無太大誤差。當然與市面上這些大型語言模型相比,還是存在一些差異,但就個人訓練的結果而言,這已經是一個很好的成績了。
model.load_state_dict(torch.load('model.ckpt'))
model.eval()
idx = 7778
input_data = tokenizer(x_test[idx], max_length=1024, truncation=True, padding="longest", return_tensors='pt').to(device)
generated_ids = model.generate(**input_data, max_len=50)
print('輸入文字:\n', x_test[idx])
print('目標文字:\n', y_test[idx])
print('模型文字:\n', tokenizer.decode(generated_ids[0]))
# ----- 輸出 ------
輸入文字:
mandsaur police tuesday filed 350page chargesheet two accused eightyearold girls gangrape case chargesheet names 92 witnesses lists 100 pieces evidence accused girl allegedly kidnapped waiting family member outside school raped secluded place
目標文字:
92 witnesses 100 evidences mandsaur gangrape chargesheet
模型文字:
[CLS] 92 witnesses 100 evidences mandsaur gangrape chargesheet [SEP]
今天我向你們講解了如何使用 PyTorch 的 Transformer 模型進行文本摘要,重點在於如何建立遮罩矩陣以及如何將 Embedding 與 Transformer 中的 Positional Encoding 合併。並且在昨天的內容中我通過公式幫助你更容易理解 Transformer 的架構和應用。
最後我們也見識到了 Warmup 加餘弦退火法進行模型訓練,以優化模型並取得良好的生成效果,這一點我們從生成的結果中,看到了當前最強大模型架構所擁有的能力。在接下來的內容中,我會告訴你如何將 Transformer 應用於預訓練模型。


 iThome鐵人賽
iThome鐵人賽